What we learned using AI agents to refactor a monolith

by Nancy Wang, Wayne Duso, K.J. Valencik
April 20, 2026 - 9 min

Related Categories
AI agents are increasingly used to refactor large codebases, but many teams lack a clear understanding of where they succeed and where they fail. At 1Password, we applied agentic tooling to a multi-million-line Go monolith, and in this blog we'll share what worked, what broke, and what it means for teams adopting AI in production systems.
Here’s the situation: 1Password runs a large Go monolith called B5. It has been the foundation of our product for years and continues to perform well in production, both in terms of reliability and scale.
Now, Unified Access is designed to support both human and agent-driven workflows at high request rates and low latency. As we continue adding and enhancing its capabilities, we need clearer service boundaries and more independent scaling characteristics. Over time, that means evolving parts of the system in a way that preserves the privacy, performance, reliability, and security properties we have already established.
Coming up with an actionable plan for tackling this problem sounded like a good job for agents.
In our case, this meant applying agentic refactoring: using AI agents to analyze, plan, and execute changes across a codebase, from dependency mapping to system decomposition.
There’s a version of this story where agentic tooling analyzes a large codebase, produces a clean extraction plan, and service decomposition follows a predictable path from there.
Parts of that story did play out as expected. We built an agentic toolchain that analyzed millions of lines of code and gave us a clear, defensible extraction order, and that work has meaningfully improved how we think about decomposing the system.
What ended up being more valuable, though, was what we learned once we applied those tools to real changes in a live production environment. That is the part that tends to get glossed over, and it is the part that actually determines whether this approach works.
Building the analysis layer
The first question we had to answer was sequencing. In a system that handles sensitive data at scale, extraction order is a correctness constraint. If you get the sequence wrong, you can introduce subtle failures that are difficult to detect and even harder to unwind later.
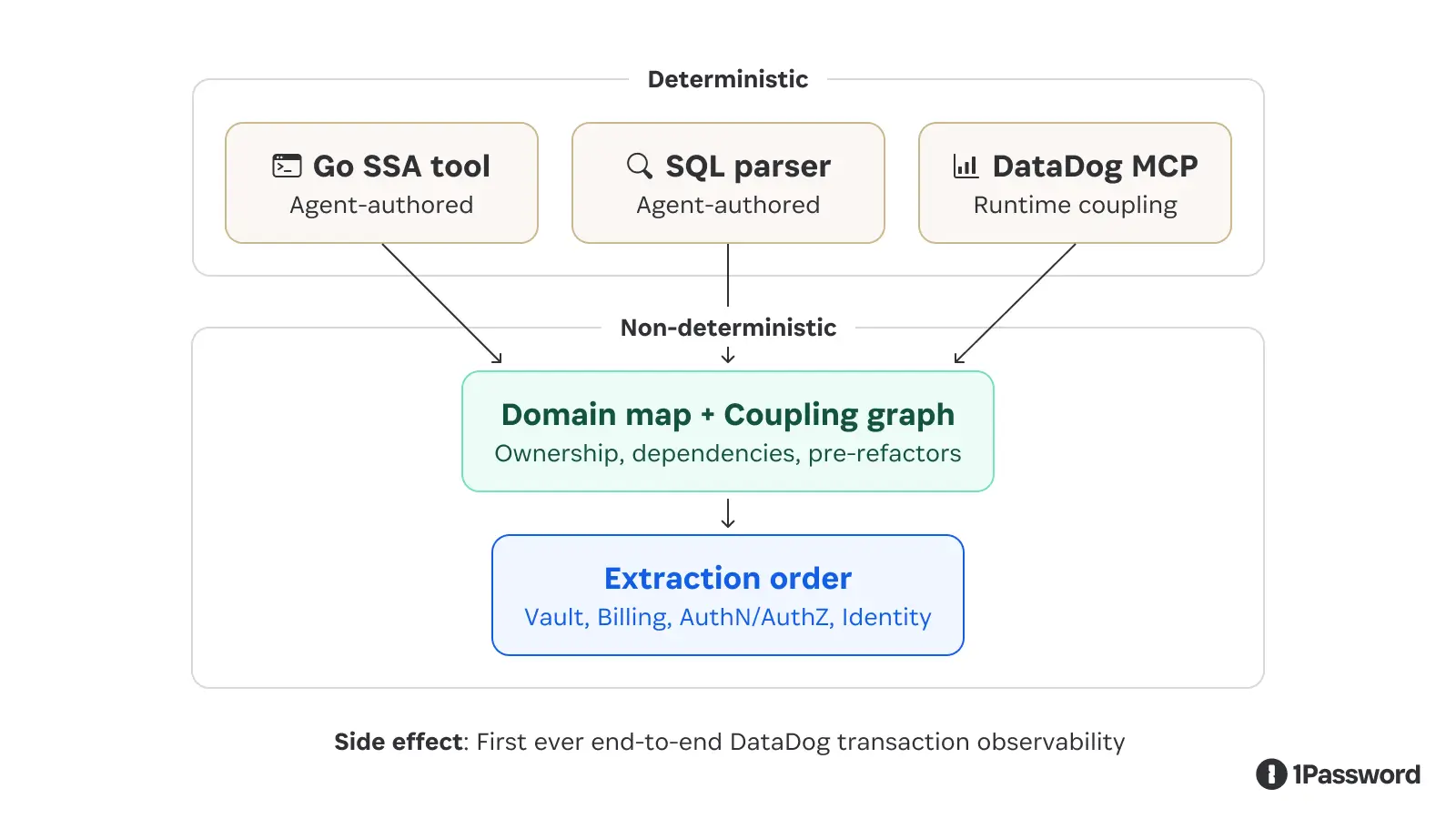
To make that problem tractable, we built an agentic toolchain that combined a few different sources of truth.
We used Go SSA analysis to understand code structure, SQL parsing to identify data dependencies, and a DataDog MCP integration to bring in runtime coupling data. Together, these gave us a domain ownership map, a coupling graph, and a prioritized extraction order.
The output largely matched what you would expect from experienced engineers looking at the system. It suggested starting with Vault, which has its own API, dataset, and security boundary, followed by Billing, then AuthN and AuthZ, with Identity remaining as the core.
One pattern that worked especially well was using agents to build deterministic tooling rather than relying on them for ongoing interpretation. In this case, agents helped write parts of the SSA analyzer, and the analyzer then produced a reproducible domain map. That distinction matters because once the tool exists, you are reasoning over a stable artifact rather than debating what the model believes the system looks like.
An unexpected benefit of this work was that the instrumentation we added to support the analysis also improved our end to end transaction visibility in DataDog, which has been useful beyond this project.
Finding the human to agent ratio
In parallel with the extraction analysis, we applied the same approach to a long-standing cleanup task in the codebase.
Our Go server used MustBegin to start database transactions, which panics on failure. That behavior made sense early on because it surfaced database issues quickly during development, but at production scale it is not the behavior you want when connections time out or request contexts are cancelled. In those cases, returning a clean error is the correct outcome.
The migration required updating more than 3,000 call sites across production and test code, which is why it had been sitting in the backlog.
The approach we took was highly structured. We generated a deterministic manifest of every call site using SSA, classified those sites into a small number of patterns, and defined explicit templates for each one. From there, we wrote a detailed playbook that described exactly how agents should execute the migration, including a list of common failure modes and clear instructions on when to stop and escalate instead of guessing. To scale execution, we ran multiple agents in parallel using git worktrees so that changes remained isolated.
Execution itself took a matter of hours. The majority of the time was spent building the tooling and writing the specification.
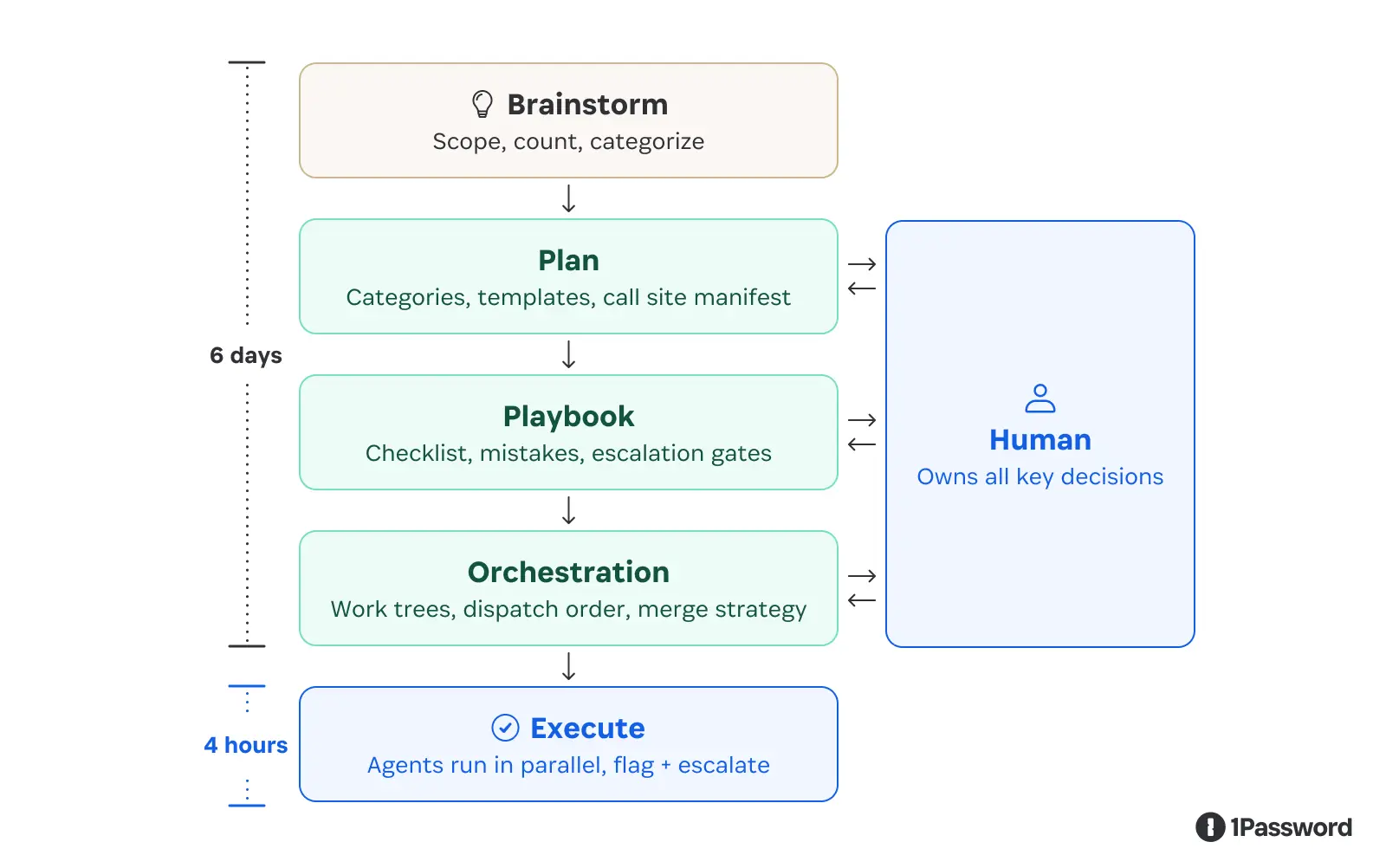
That ratio is the important part. When the work is fully specified and bounded, agents are both fast and accurate. When they encounter something outside the specification, the system is designed to surface that rather than attempting to resolve it implicitly.
Where agents need stronger constraints
We then moved on to a more complex task, which was extracting a service from the monolith.
Even for a relatively small service, this kind of work requires coordinated changes across schema evolution, read and write paths, deployment sequencing, and shared data contracts. These are interdependent decisions that need to happen in the right order. The primary issue we saw with this task was related to sequencing and invariants.
For example, the agent would attempt to backfill UUID columns before updating the code responsible for inserting new rows. That sequence introduces silent data loss, even if the underlying system is otherwise well designed. In other cases, it treated shared tables as if they were independently owned by the new service, which would have created conflicts at deployment time. These patterns persisted even when we provided explicit instructions about ordering and constraints.
We also saw a recurring behavior that we described internally as “speculation.” When the agent lacked sufficient context, it filled in the gaps with assumptions that appeared reasonable but were not verified. In one case, it inferred that a particular identifier format was a ULID and propagated that assumption through a series of changes, which ultimately required rolling back the entire session.
The pattern that works is using agents to produce deterministic artifacts, then forcing execution through those constraints. For instance, in Cursor, we see lots of customers use Plan Mode with a bigger, slower model (like GPT5.4 or Opus) to produce a concrete plan.md file, edit the file as needed, and then actually build with a smaller, faster model that is excellent at coding (like Composer)." - Tido Carriero, VP of Engineering, Cursor
For this class of work, the productivity gains were real but more modest. In practice, we saw something close to a 20-30% improvement. The agents were helpful, but they did not replace the need for careful coordination and review.
This points to a broader shift we’re seeing at 1Password. AI agents are becoming a new class of actor in systems, one that introduces non-determinism, persistence, and scale that traditional models were not designed to handle. That has implications not just for engineering workflows, but for how access and trust are managed across systems.
Lessons for teams using AI agents in code
There are a number of lessons other teams can take away from 1Password’s experience, and their applications extend beyond this single use case.
Lesson 1: The bottleneck for agentic refactoring is not code generation
Agents are very effective at reading code, analyzing structure, and drafting changes. Where things become difficult is in managing sequences of decisions that have ordering constraints or are difficult to reverse. This includes schema changes, deployment sequencing, and shared state boundaries. If those are not handled correctly, the system will fail regardless of how clean the generated code is.
Lesson 2: Non-determinism needs to be carefully contained
Language models are non-deterministic, which is part of what makes them useful. In the context of production migrations, however, that variability becomes a source of risk. The pattern that has worked well for us is to use agents to build deterministic tools, such as analyzers and manifests, and then constrain subsequent work to those outputs. This creates a stable foundation even when the agents themselves are not fully predictable.
Lesson 3: Incomplete specifications lead to implicit ones
When an agent does not have enough context, it will fill in the gaps, often in ways that are locally reasonable but globally incorrect. The only reliable way to address this is to make the specification explicit, including invariants, ordering constraints, and clear escalation paths for anything that falls outside the defined patterns.
Another important shift is around how to think about coverage. The goal is not to have the agent handle every possible case. The goal is to have it execute confidently on well-understood patterns and escalate quickly when it encounters ambiguity. This requires being intentional about where automation stops and human judgment takes over.
Lesson 4: Parallelism only works when isolation has already been solved
Running multiple agents at once can be very effective, but only when changes are independent and conflicts are structurally eliminated. Otherwise, you end up increasing the surface area for inconsistency rather than reducing execution time.
How this impacts 1Password’s agentic approach
We are rolling out agentic tooling across the engineering organization with a clear understanding of where it provides leverage.
We know that agents are most effective when the problem is well specified and that deterministic tooling provides the constraints that make that possible. Engineers remain responsible for defining system boundaries, modeling dependencies, and ensuring that sequencing is correct.
These insights will help us shift the nature of the work we allocate to engineers, understanding that the highest leverage activities are not writing code or prompting models, but defining systems in a way that can be executed safely and predictably.
The problems we are working on, including decomposing a production system under live traffic and structuring multi-agent execution, do not yet have well-established playbooks. We are building those in real time, and that is where most of the interesting engineering work is happening.
If that is the kind of problem you enjoy working on, we are hiring.

